17. 总结
总结
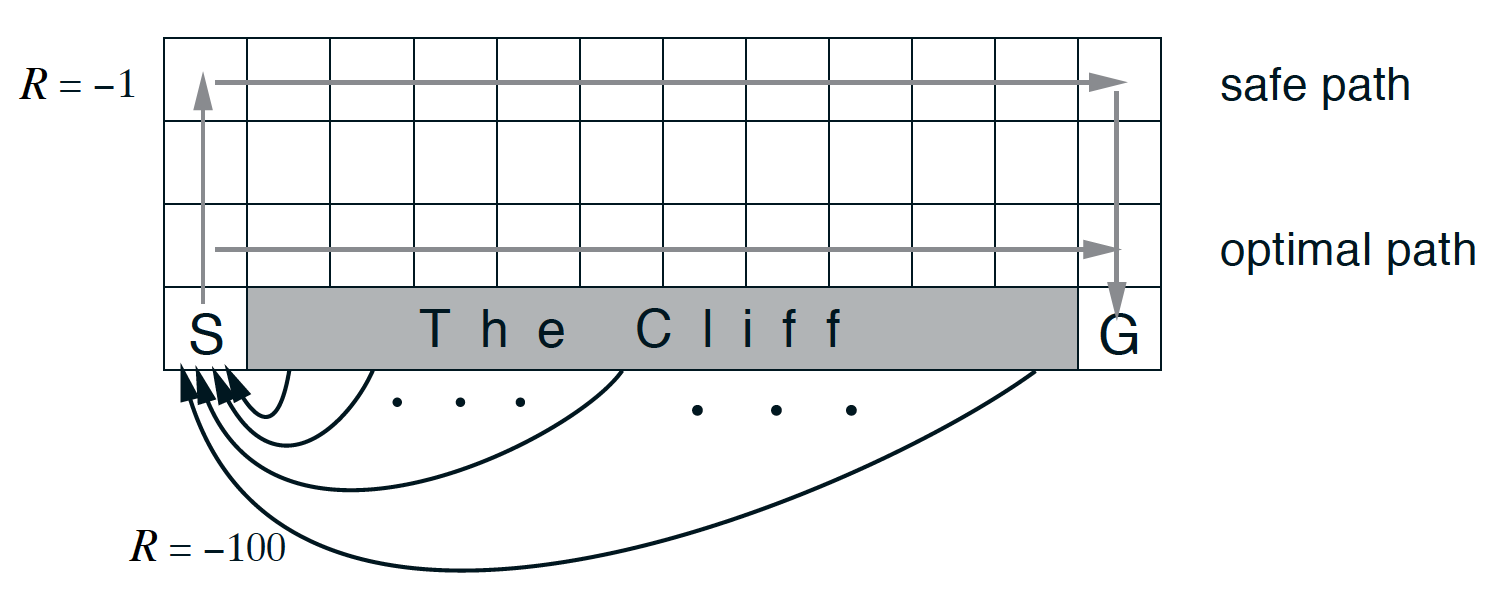
‘悬崖行走任务(Sutton 和 Barto,2017 年)'
TD 预测:TD(0)
- 虽然蒙特卡洛 (MC) 预测方法必须等到阶段结束时才能更新值函数估值,但是时间差分 (TD) 方法在每个时间步之后都会更新值函数。
- 对于任何固定策略,一步 TD(或 TD(0))保证会收敛于真状态值函数,只要步长参数 \alpha 足够小。
- 在实践中,TD 预测的收敛速度比 MC 预测得要快。

TD 预测:动作值
-(在此部分,我们讨论了估算动作值的 TD 预测算法。和 TD(0) 算法相似,该算法保证会收敛于真动作值函数,只要步长参数 \alpha 足够小。)
TD 控制:Sarsa(0)
- Sarsa(0)(或 Sarsa)是既定策略 TD 控制方法。它保证会收敛于最优动作值函数 q_*,只要步长参数 \alpha 足够小,并且所选的 \epsilon 满足有限状态下的无限探索贪婪算法 (GLIE) 条件。

TD 控制:Sarsamax
- Sarsamax(或 Q 学习)是一种新策略 TD 控制方法。它会在保证 Sarsa 算法会收敛的相同条件下保证收敛于最优动作值函数 q_*。

TD 控制:预期 Sarsa
- 预期 Sarsa 是一种新策略 TD 控制方法。它会在保证 Sarsa 和 Sarsamax 算法会收敛的相同条件下保证收敛于最优动作值函数 q_*。

分析性能
- 既定策略 TD 控制方法(例如 Sarsa 和 Sarsa)比新策略 TD 控制方法(例如 Q 学习)的在线性能好。
- 预期 Sarsa 通常性能比 Sarsa 好。